
EPM Data Integration – Pipeline
Case Study
A client expressed the need for an interface with functionality that would allow non-technical professionals to run daily batches. These batches could include tasks like pulling Actuals, updating the Chart of Accounts (CoA), or refreshing the Cost Centre structure and running the business rules, among others, from the source System.
While seeking a solution, we explored numerous alternatives within Data Integration. However, the challenge emerged as several intricate steps were involved, necessitating individuals to possess a certain level of technical understanding of the Data Integration tool.
Solution
Exciting developments ensued when Oracle introduced a new feature known as “Pipeline.”
Pipeline in Data Integration
This innovative addition empowers users to seamlessly orchestrate a sequence of jobs as a unified process. Moreover, the Pipeline feature facilitates the orchestration of Oracle Enterprise Performance Management Cloud jobs across instances, all from a single centralized location.
By leveraging the power of the Pipeline, you can gain enhanced control and visibility throughout the entire data integration process, encompassing preprocessing, data loading, and post-processing task.
Yet, this merely scratches the surface. The Pipeline introduces a multitude of potent benefits and functionalities. We’re delving into an in-depth exploration of this novel feature to uncover its potential in revolutionizing your data integration process.
Enterprise data within each application is grouped as multiple dimensions. Each Dimension has its own Data chain. Registering New application results in the creation of various objects and associated dimensions. An A
Note the following Pipeline considerations
- Only administrators can create and run a Pipeline definition.
- Pipeline is a replacement for the batch functionality in Data Management and can be migrated automatically to the Pipeline feature in Data Integration.
- For file-based integrations to a remote server in the Pipeline when a file name is specified in the pipeline job parameters., the system copies any files automatically from the local host to the remote server automatically under the same directory.
This function applies to the following Oracle solutions:
- Financial Consolidation and Close
- Enterprise Profitability and Cost Management
- Planning
- Planning Modules
- Tax Reporting
Proof of Concept
EPM batches to run sequentially are:
Stage 1 – Load Metadata
- Load Account Dimension
- Load Entity Dimension
- Load Custom Dimension
- Clear current month Actuals (to remove any nonsense numbers if any)
Stage 2 – Load Data
- Load Trial balance from Source
Stage 3 – Run Business Rule
- Run Business rule to perform Aggregate & Calculations.
The workflow for creating and running a Pipeline process is as follows:
- Defining Pipeline


- Pipeline Name, Pipeline Code, maximum Parallel Jobs
- Variable page to set the out-of-box (global values) for Pipeline are available from which you can set parameters at runtime. Variables can be pre-defined types like: “Period”, “Import Mode” etc.

- You can utilize Stages in the Pipeline editor to cluster similar or interdependent Jobs from various applications together within a single unified interface. Administrators can efficiently establish a comprehensive end-to-end automation routine, ready to be executed on demand as part of the closing process.
Pipeline Stages & Container for multiple jobs as shown below:
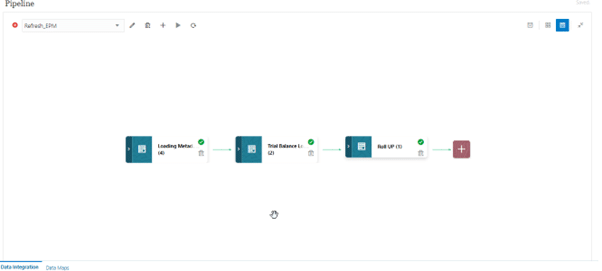

Stages & Jobs example

The new stages can be added by simply using the Plus card located at the end of the current card sequence.
![]()
- On the Run Pipeline page, Complete the variable runtime prompts and then click As shown below:
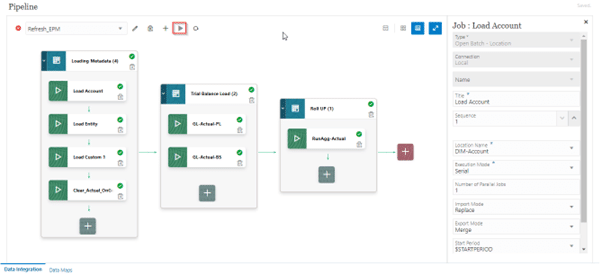
Variable Prompts

When the Pipeline is running, you can click the status icon to download the log. Customers can also see the status of the Pipeline in Process Details. Each individual job in the Pipeline is submitted separately and creates a separate job log in Process Details.
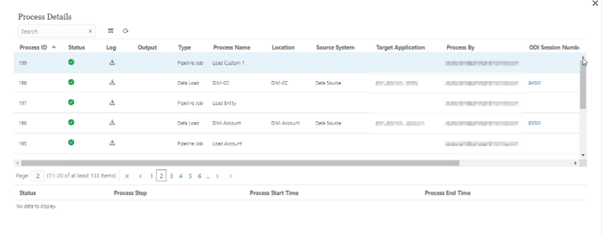
Users can also schedule the Pipeline with the help of Job Scheduler.


Variable Prompt

Review

Amir Kalawant
